What Is a Bloom Filter?
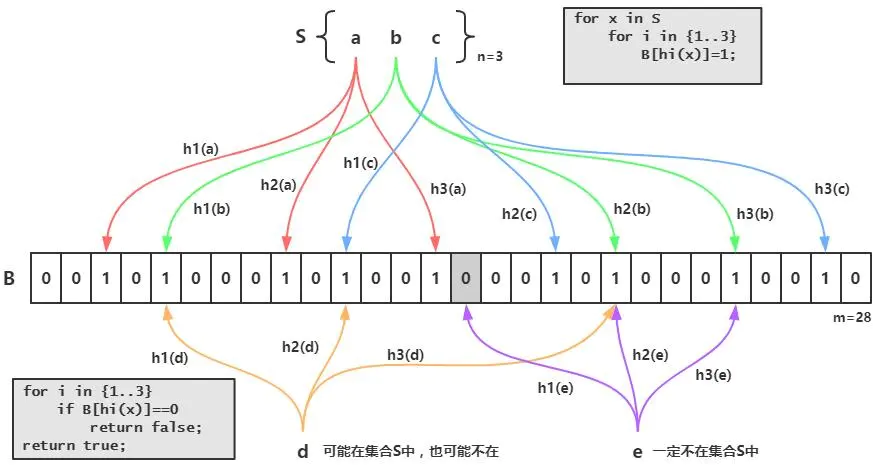
A Bloom filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set. When an element is added, it is hashed by K independent hash functions, each mapping the element to a position in a bit array, which is then set to 1.
To query membership, the same K positions are checked:
- If any bit is 0 → the element is definitely not in the set.
- If all bits are 1 → the element is probably in the set (false positives are possible).
The key difference from a single-hash bitmap: using K hash functions spreads the load and significantly reduces collision probability.
Cache Penetration
Cache penetration occurs when requests for non-existent keys bypass the cache entirely and hit the database on every call. A Bloom filter is a classic solution: check the filter first, and if the element is definitely absent, return early without touching the database.
Limitations of Bloom Filters
The speed and space efficiency come with two trade-offs:
False positives — An element that was never inserted may still pass the membership check if all K bit positions happen to be set by other elements. One mitigation: maintain a separate whitelist for elements known to produce false positives.
No deletion — Setting a bit back to
0would affect other elements that share that position. If deletion is required, use a Counting Bloom Filter instead, which stores counters rather than single bits.
How I Implemented It (Node.js)
| |
Summary
- Java’s Guava library ships a ready-to-use Bloom filter implementation.
- The hash function above follows the double-hashing technique described in the referenced paper — only two hash functions are needed to achieve optimal false-positive rates.
Reference: Less Hashing, Same Performance — Kirsch & Mitzenmacher (2008)